
Mitigating microarchitectural timing channels with hardware-provided operations
This page shows data gathered from a quantitative study of timing channels exploiting microarchitectural state on multiple generation of Intel and ARM processors. We measure channel capacities of the raw channels, i.e., without any countermeasures applied, as well as with all architected scrubbing measures (including disabling the data prefetcher).
In the wake of the Spectre attack, Intel released a microcode update with a suite of defence mechanisms, collectively referred as indirect branch control (IBC). As IBC performs a degree of sanitising of the branch predictor, this could be a possible mechanism for eliminating the channels we observe. We therefore include the IBC as part of the hardware scrubbing measures on the tested x86 platforms.
Leakage is evaluated in a covert channel scenario. There are two security domains which time-share a processor core. One domain, Hi contains secrets and is confined by the system's security policy, meaning that the secrets must not leak outside. A second domain, Low, can communicate freely with the outside world. The attacker controls a spy process running in Low and has managed to place a Trojan in Hi. The Trojan has access to the secret and is actively trying to leak it via the channel under investigation.
Channels
We investigate five microarchitectural timing channels:
- L1-D-cache channel
- L1-I-cache channel
- TLB channel (not demonstrated previously on a tagged TLB)
- Branch-target buffer (BTB) channel (not demonstrated previously)
- Branch-history buffer (BHB) channel
We also examine the mitigated timing channel without Intel's Spectre fix for comparing the effectiveness of Intel's IBC mechanism.
The implementation of the channels is specific to the exploited microarchitectural feature, and explained in the respective sections. What is common is that we use prime-and-probe attacks, where the spy primes the microarchitectural component to force it into a defined state, waits until the Trojan executed for a time slice, and then probes the state for the effect of the Trojan's execution.
For example, the spy primes the D-cache by traversing a buffer large enough to fill it with its own data. The Trojan touches its own buffer, to replace a specific number of cache lines with its own data, this number is the input symbol (s) of the channel. When probing, the spy measures its own execution time, which depends on the number of cache lines replaced by the Trojan; the measured probe time is the output symbol. In the absence of a channel, the output symbol will be uncorrelated to the input symbol.
Hardware Platforms
| Name | Haswell | Skylake | Sabre | Hikey |
|---|---|---|---|---|
| Architecture | x86 | x86 | ARMv7 | ARMv8 |
| Microarchitecture / Core | Haswell | Skylake | Cortex A9 | Cortex A53 |
| Processor / SoC | i7-4700 | i7-6700 | i.MX6 | Kirin 620 |
| Vintage | 2013 | 2015 | 2011 | 2015 |
| Clock rate | 3.4 GHz | 3.4 GHz | 0.8 GHz | 1.2 GHz |
| Execution mode | 64 bit | 64 bit | 32 bit | 32 bit |
| Time slice | 1 ms | 1 ms | 1 ms | 1 ms |
| L1-D size | 32 KiB | 32 KiB | 32 KiB | 32 KiB |
| L1-D sets × associativity | 64×8 | 64×8 | 256×4 | 128×4 |
| L1-I size | 32 KiB | 32 KiB | 32 KiB | 32 KiB |
| L1-I sets × associativity | 64×8 | 64×8 | 256×4 | 256×2 |
| I+D TLB size (entries) | 64+64 | 128+64 | 32+32 | 10+10 |
| Unified TLB size (entries) | 1024 | 1536 | 128 | 512 |
| BTB size (entries) | ??? | ??? | 512 | 256 |
Results
For each channel and evaluation platform we show the channel matrix, which represents the conditional probability of observing an output symbol (vertical axis) given an input symbol (horizontal axis). We represent the channel matrix as a heat map, brighter colours indicating a higher probability.
In the absence of a channel, the output symbol should be uncorrelated to the input symbol, which will result in a channel matrix without any horizontal variation. Any such variation is a clear indication of a channel.
We quantify the channel by computing the mutual information (MI), 𝓜, of the channel, which represents the average number of bits of information a computationally-unlimited attacker can learn from each input by observing the output. For the mitigated channels we also provide 𝓜0, which is the 95% upper confidence interval on the capacity of the apparent channel resulting from purely random sampling error. If 𝓜>𝓜0 we say that the observations are inconsistent with MI being zero and hence there is a leak, else the dataset contains no evidence of a leak. With each channel, n is the number of measurements made for each input symbol.
We use the leakiEst, a tool for estimating information leakage, for calculating the MI 𝓜 and the 𝓜0.
We show all channel matrices and capacities here, followed by a summary of the results.
L1 D-cache channel
This is the timing channel created by domains competing for lines in the data cache. We use a prime-and-probe attack from the Mastik toolkit, where spy and Trojan read data from a buffer large enough to cover the cache.
| Platform | No migitation | With mitigation |
|---|---|---|
|
Haswell (Intel i7-4770) 64bit |
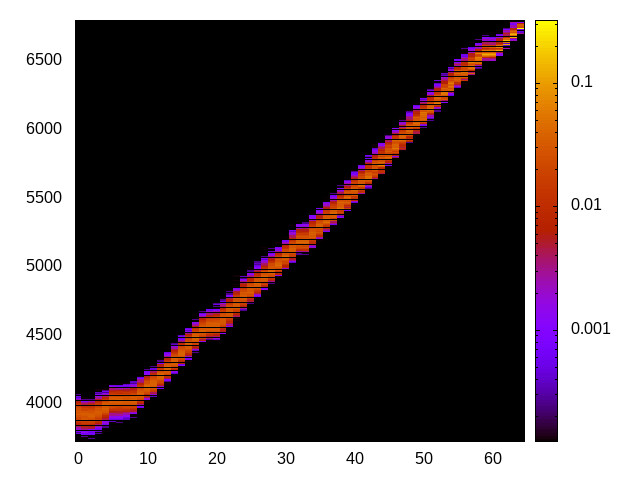
|
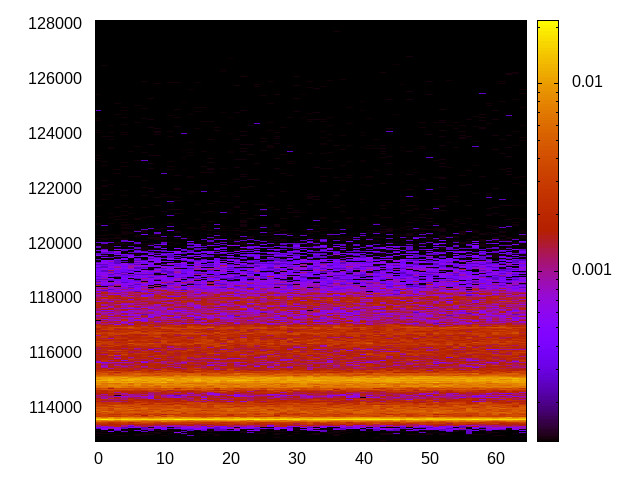
|
|
Skylake (Intel i7-6700) 64bit |
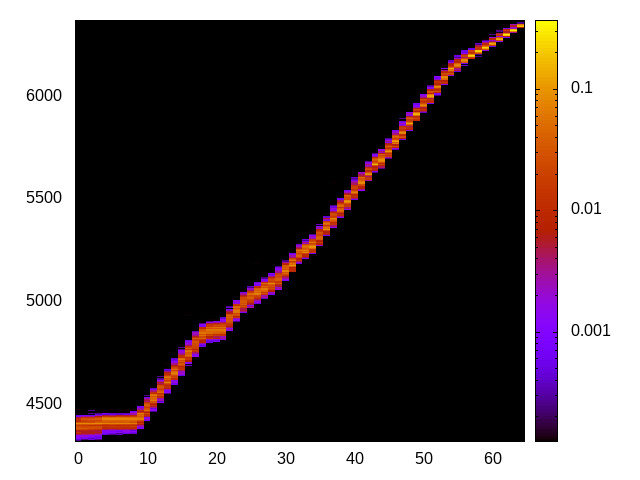
|
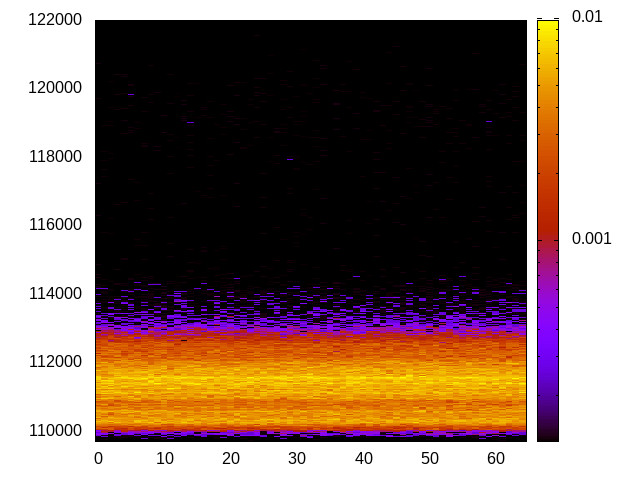
|
|
Sabre (ARMv7 Cortex A9) 32bit |
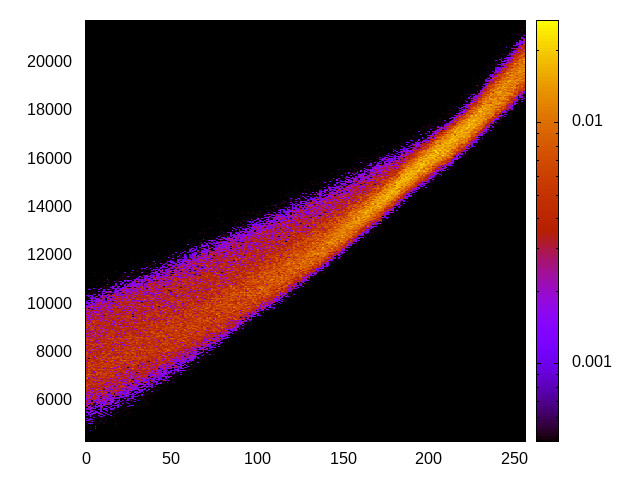
|
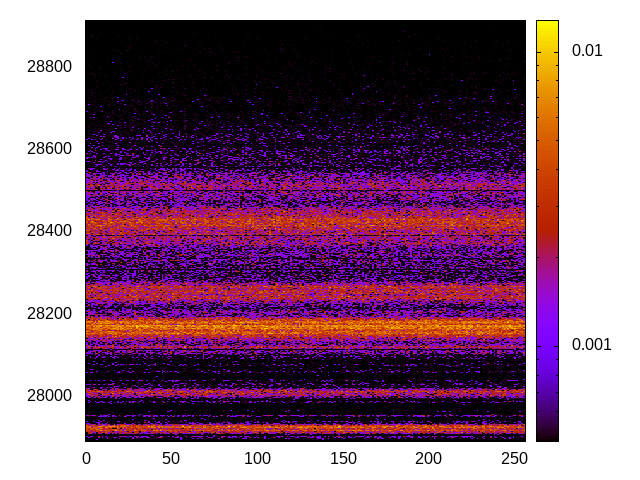
|
|
Hikey (ARMv8 Cortex A53) 32bit |
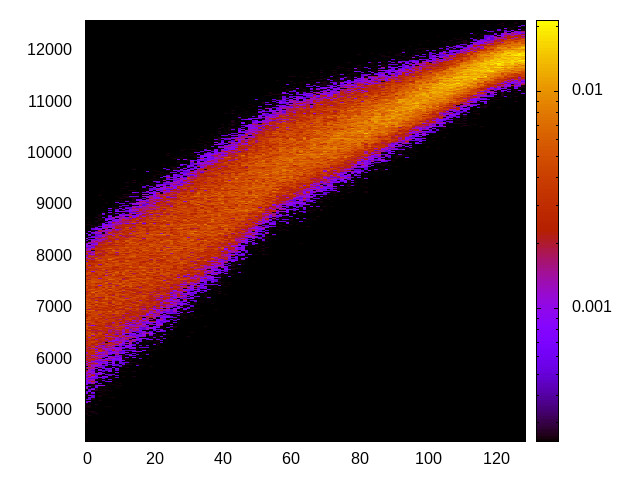
|
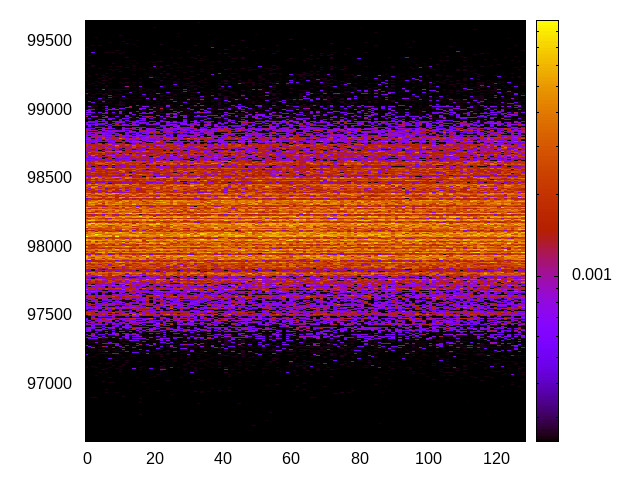
|
L1 I-cache channel
This is the timing channel created by domains competing for lines in the instruction cache. We use a prime-and-probe attack from the Mastik toolkit, where spy and Trojan execute a chain of jumps from a buffer large enough to cover the cache.
| Platform | No migitation | With mitigation |
|---|---|---|
|
Haswell (Intel i7-4770) 64bit |
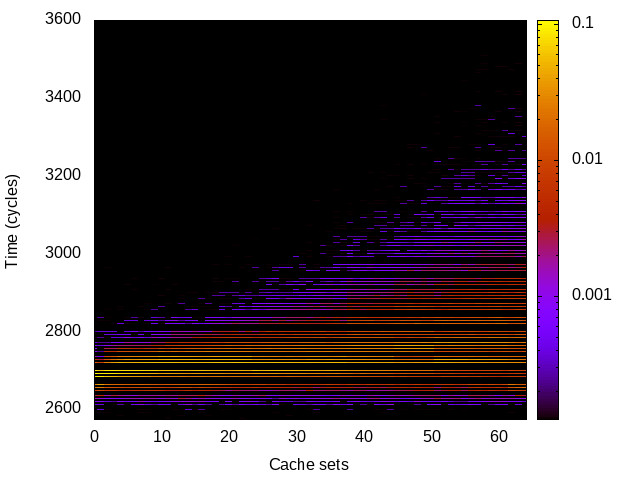
|
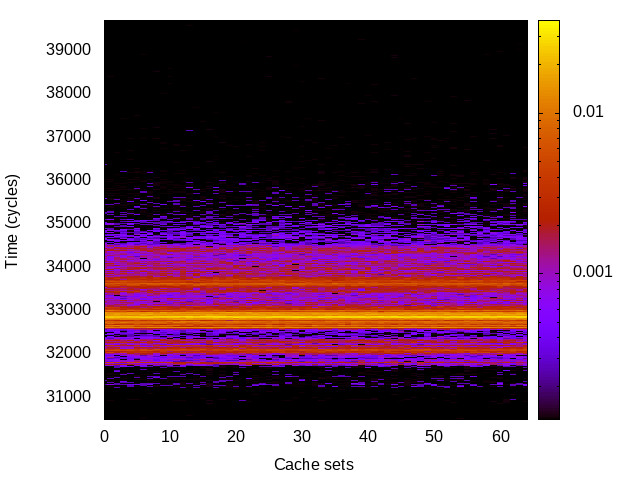
|
|
Skylake (Intel i7-6700) 64bit |
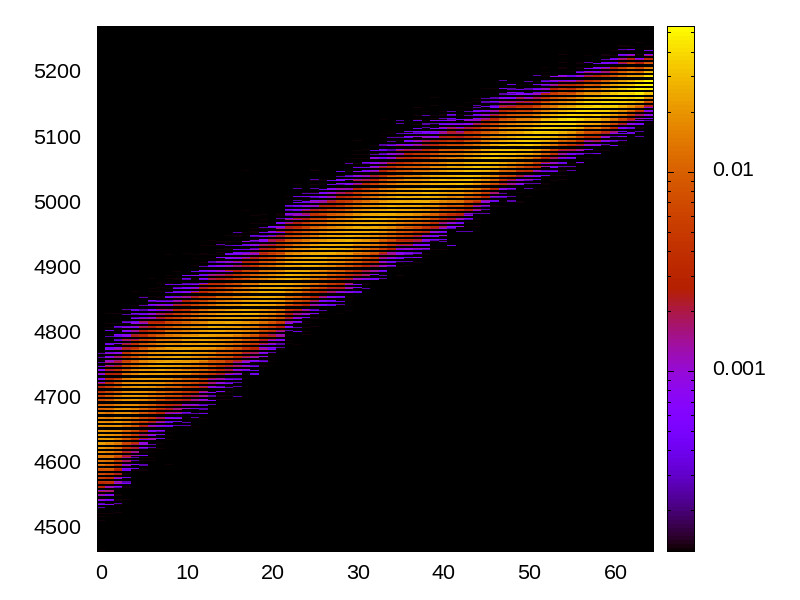
|
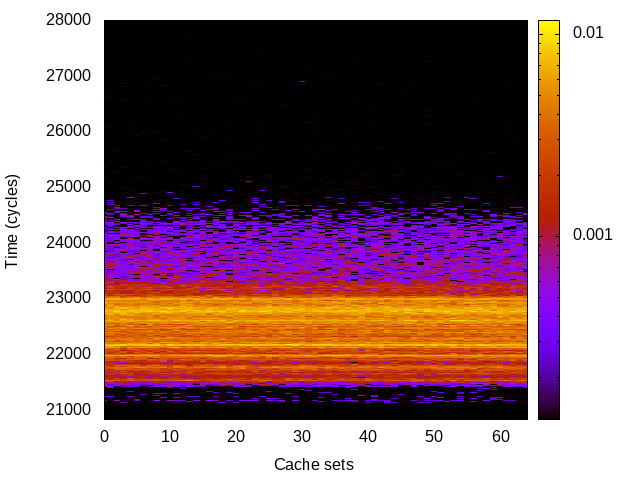
|
|
Sabre (ARMv7 Cortex A9) 32bit |
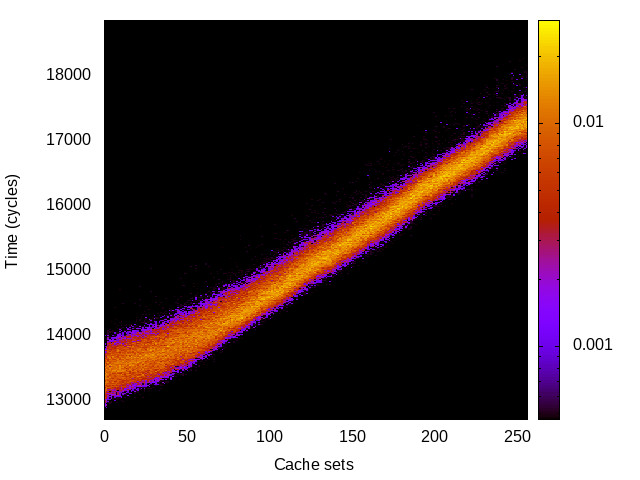
|
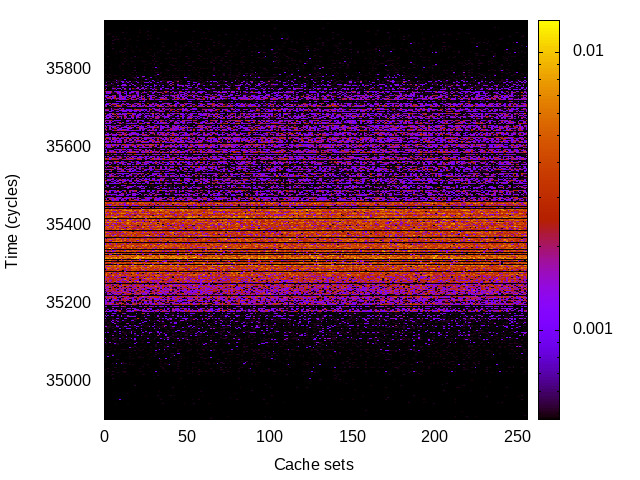
|
|
Hikey (ARMv8 Cortex A53) 32bit |
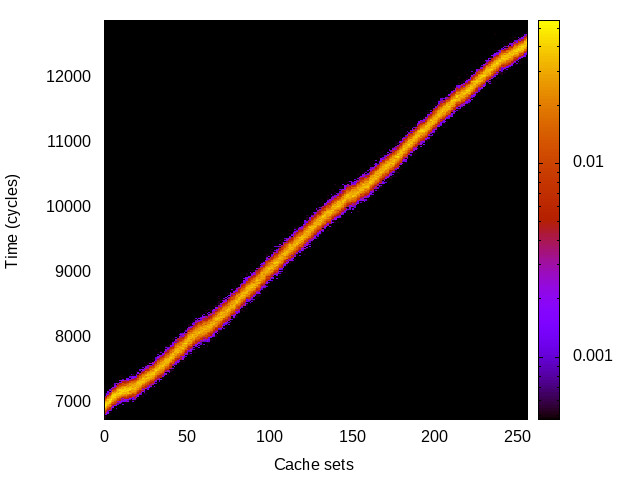
|
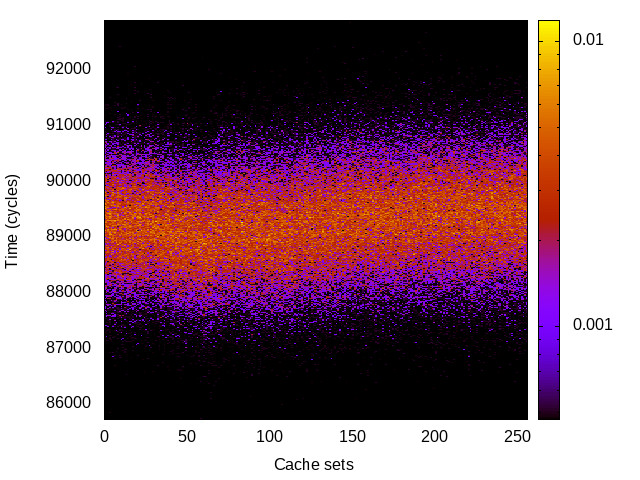
|
TLB channel
This is the timing channel created by domains competing for entries in the tagged TLB. We use a prime-and-probe attack, where spy and Trojan read from a set of pages large enough to use half the available TLB entries (we use half the TLB to avoid self-interference).
| Platform | No migitation | With mitigation |
|---|---|---|
|
Haswell (Intel i7-4770) 64bit |
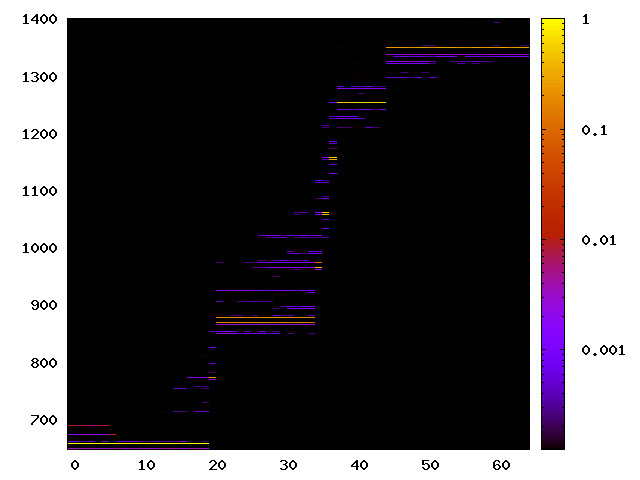
|
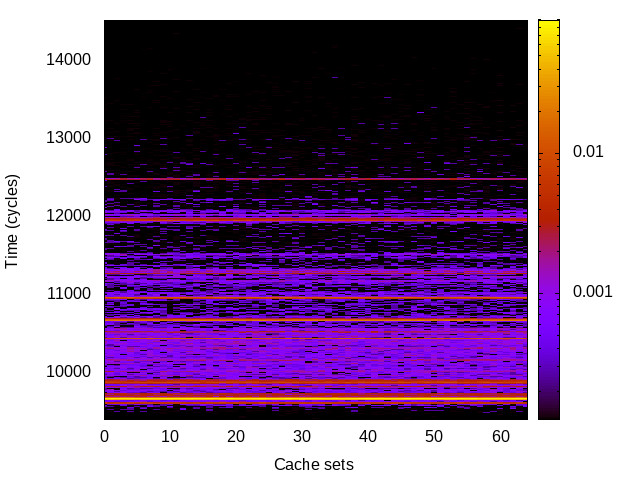
|
|
Skylake (Intel i7-6700) 64bit |
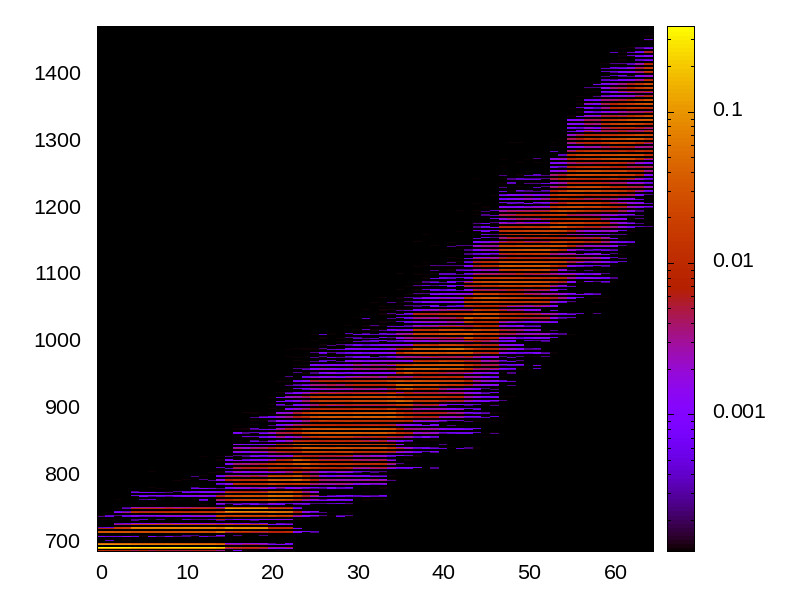
|
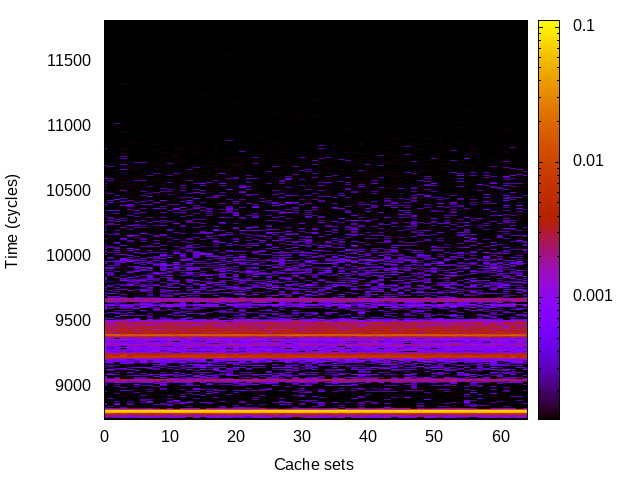
|
|
Sabre (ARMv7 Cortex A9) 32bit |
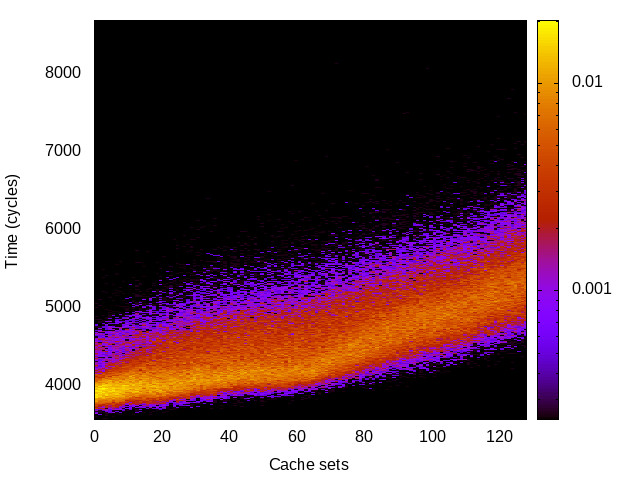
|
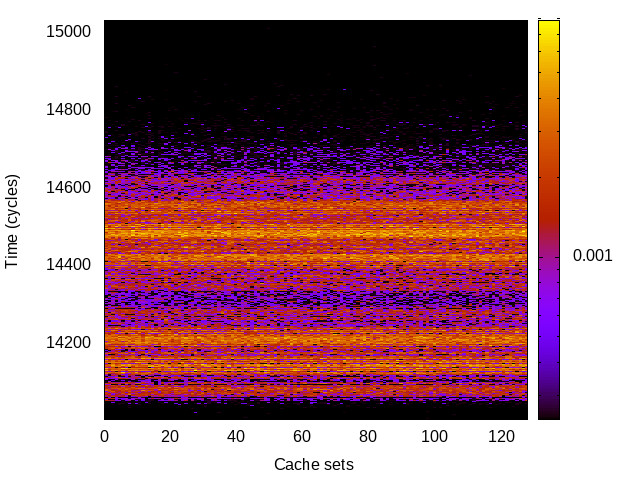
|
|
Hikey (ARMv8 Cortex A53) 32bit |
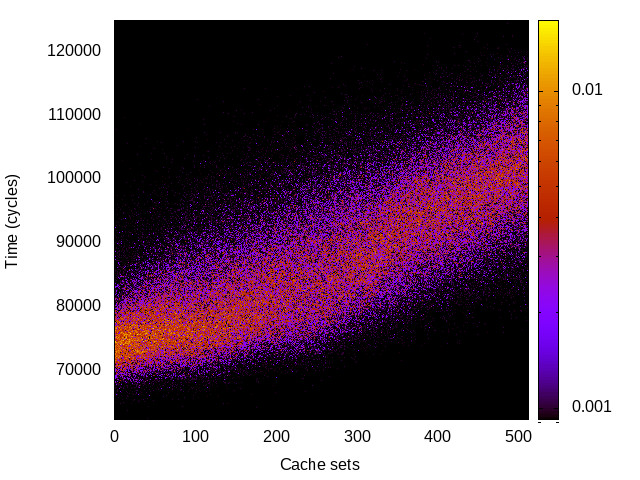
|
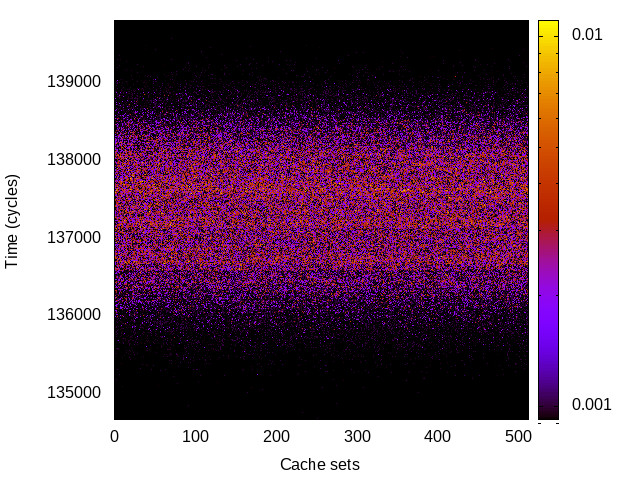
|
BTB channel
This is the timing channel created by domains competing for entries in the buffer of branch targets contained in the branch-predictor unit. We use a prime-and-probe attack, where spy and Trojan execute a set of chained branch instructions, sufficient to fill the BTB.
| Platform | No migitation | With mitigation |
|---|---|---|
|
Haswell (Intel i7-4470) 64bit |
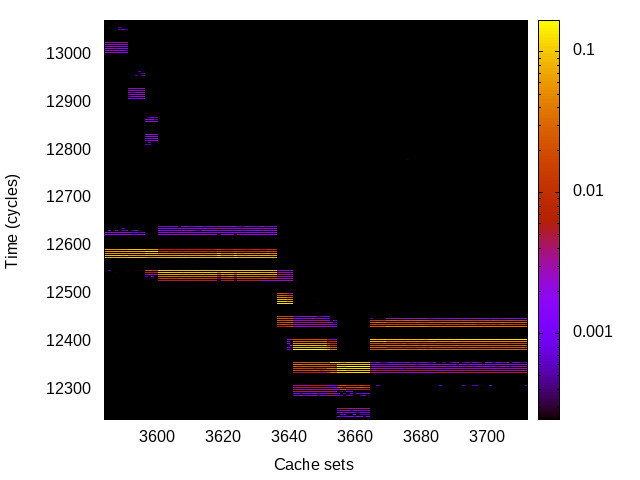
|
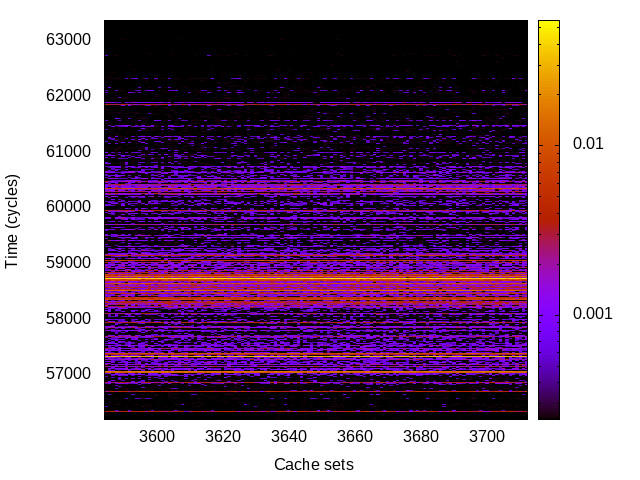
|
|
Skylake (Intel i7-6700) 64bit |
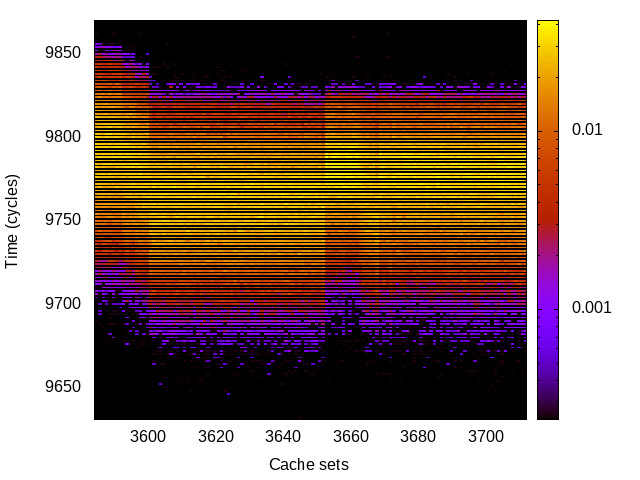
|
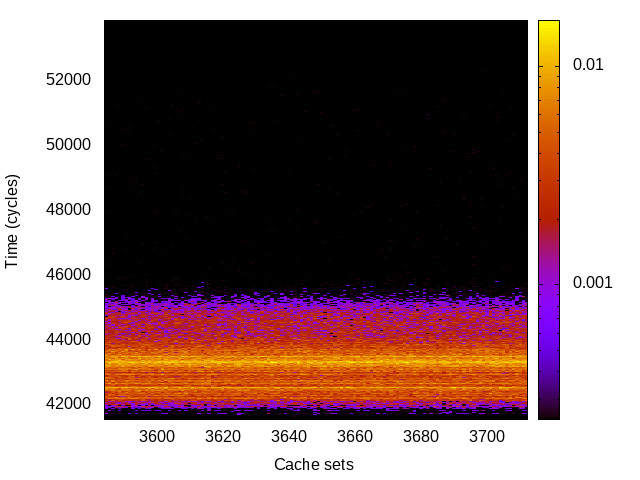
|
|
Sabre (ARMv7 Cortex A9) 32bit |
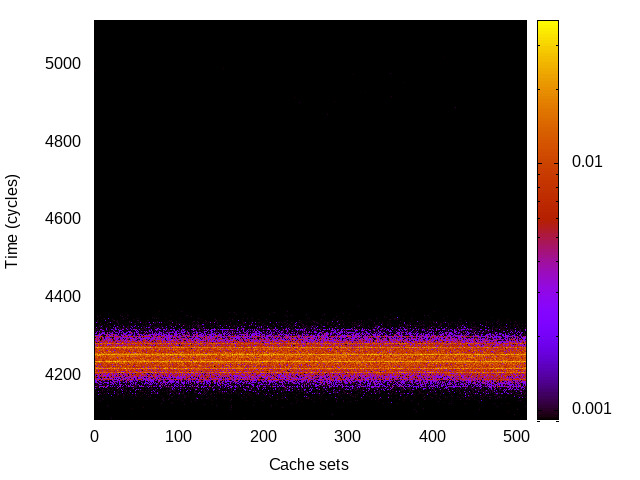
|
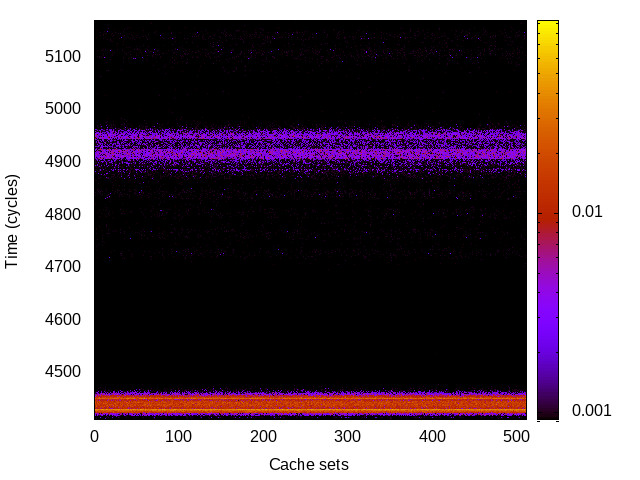
|
|
Hikey (ARMv8 Cortex A53) 32bit |
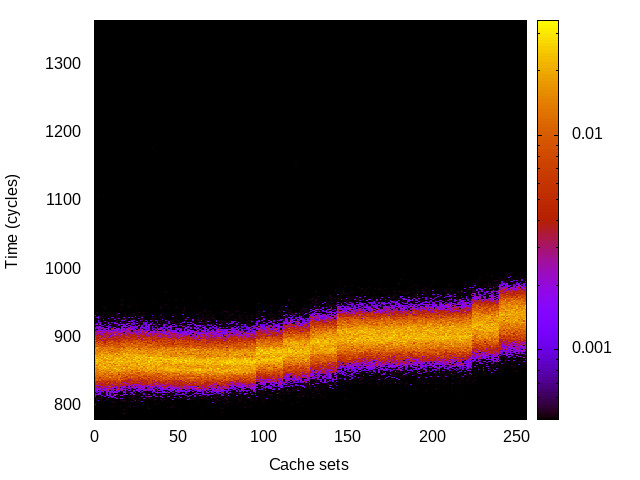
|
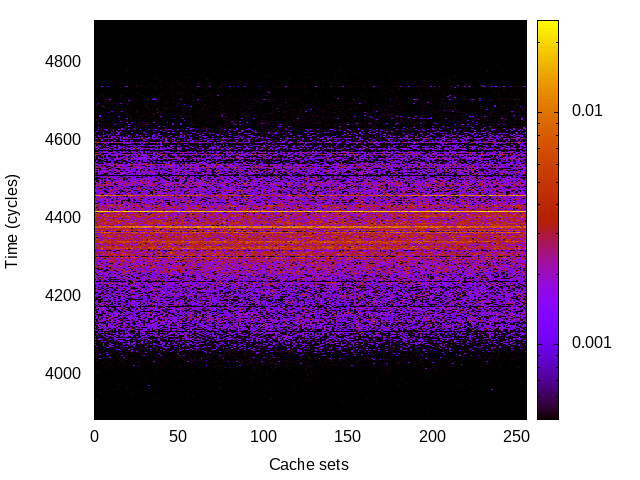
|
BHB channel
This is the timing channel created by the branch predictor
remembering whether a particular branch was taken (this is
inherently a single-bit channel). The attack includes a
sequence of conditional branches that are always taken, to set
the history to a known state. This is followed by a branch that
conditionally skips over 256 nop instructions. The
Trojan encodes a single bit by training the prediction for the
last branch. The spy measures the cost of executing the
nop instructions, a mis-predict increases latency.
| Platform | No migitation | With mitigation |
|---|---|---|
|
Haswell (Intel i7-4770) 64bit |
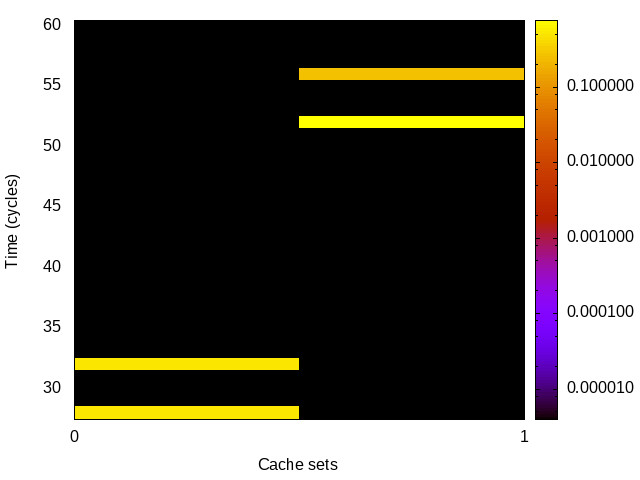
|
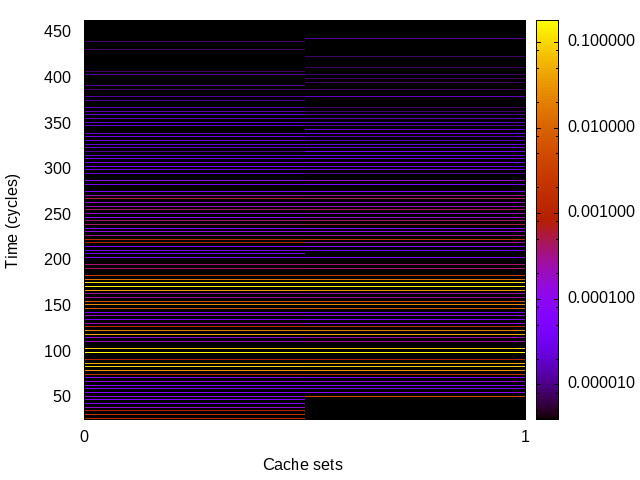
|
|
Skylake (Intel i7-6700) 64bit |
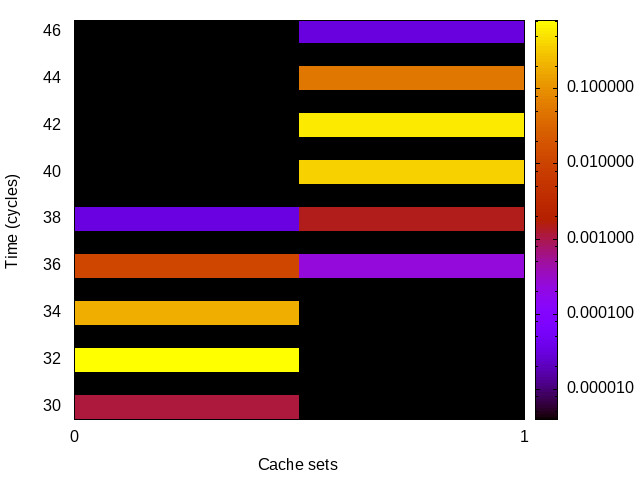
|
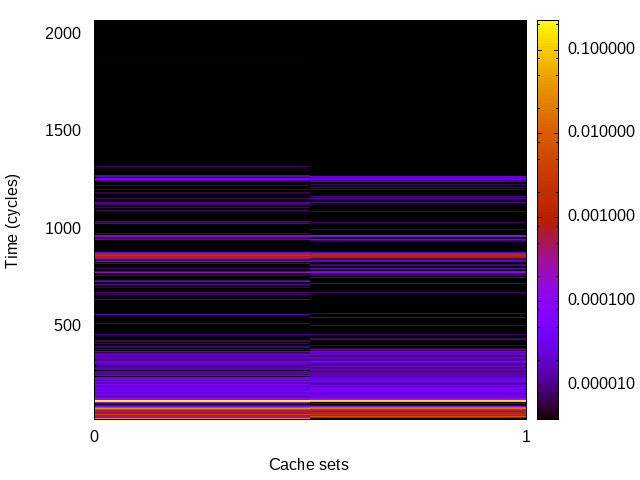
|
|
Sabre (ARMv7 Cortex A9) 32bit |
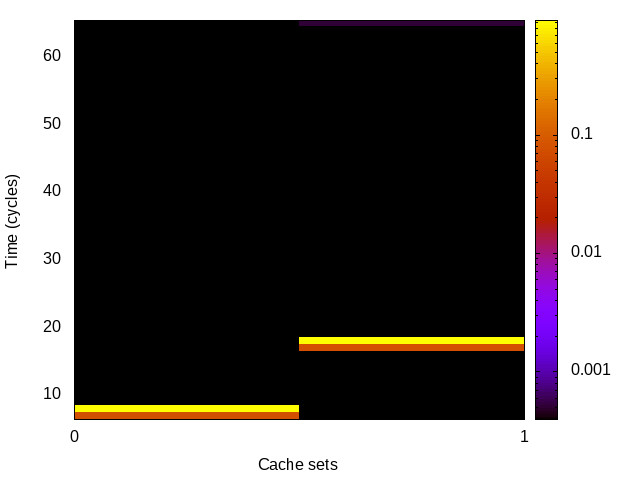
|
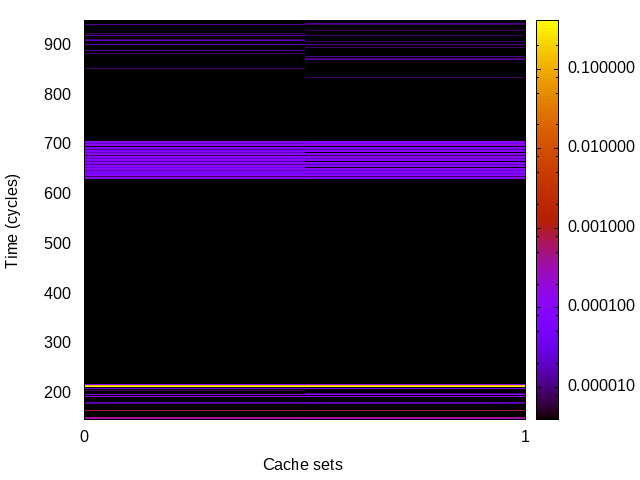
|
|
Hikey (ARMv8 Cortex A53) 32bit |
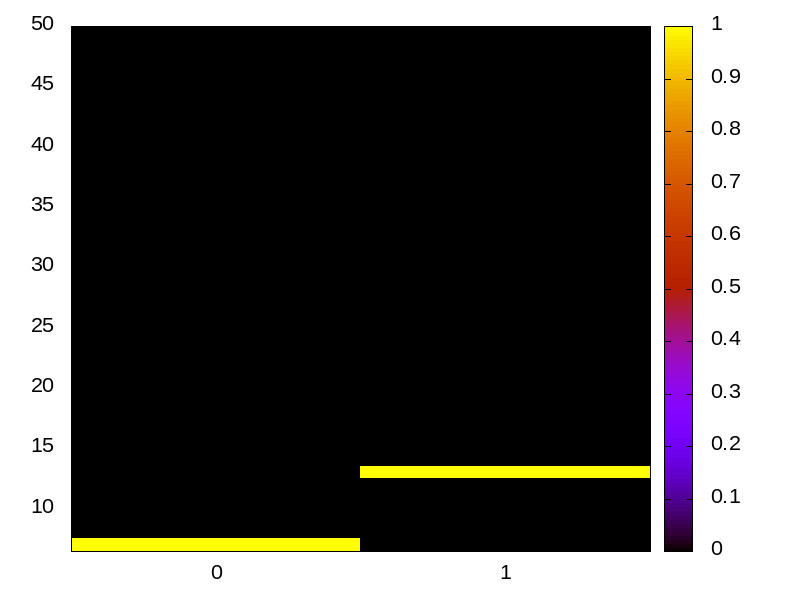
|
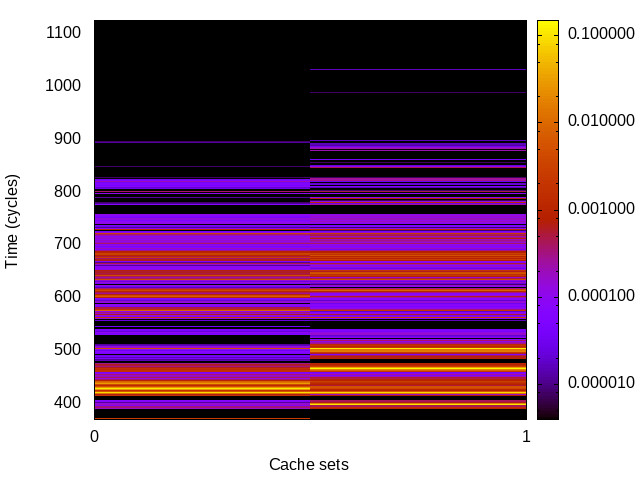
|
Mitigated timing channel without Intel's Spectre Fix (IBC)
As IBC performs a degree of sanitising of the branch predictor, the timing channels could still be observable without the IBC enabled. Thus, we re-run the instruction-related attacks on the Intel platforms to find out whether the channels remain without using the IBC.
| Attack | Haswell | Skylake |
|---|---|---|
| L1 I-cache |
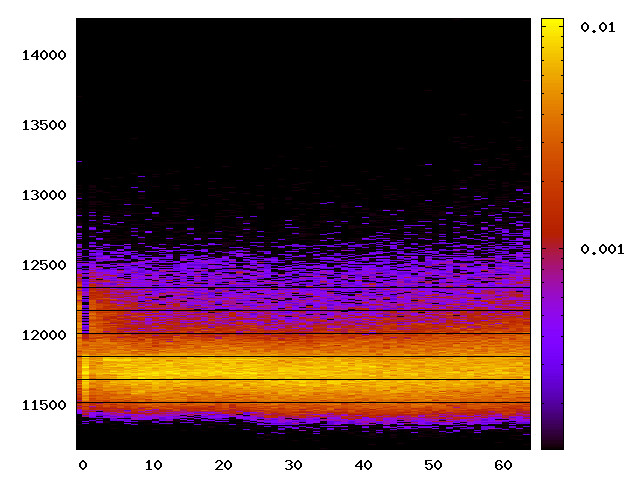
|
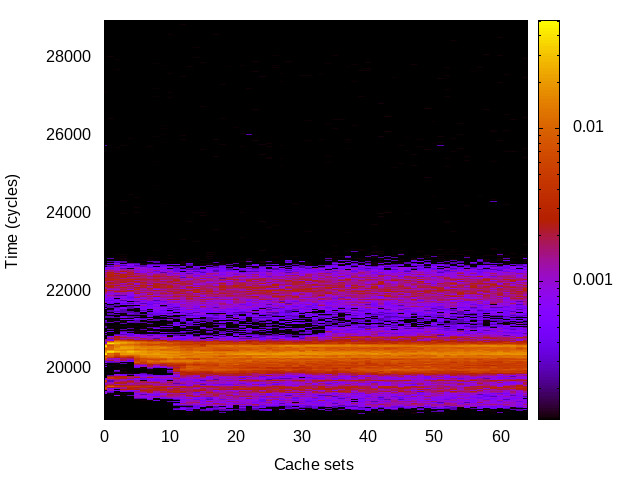
|
| BTB |
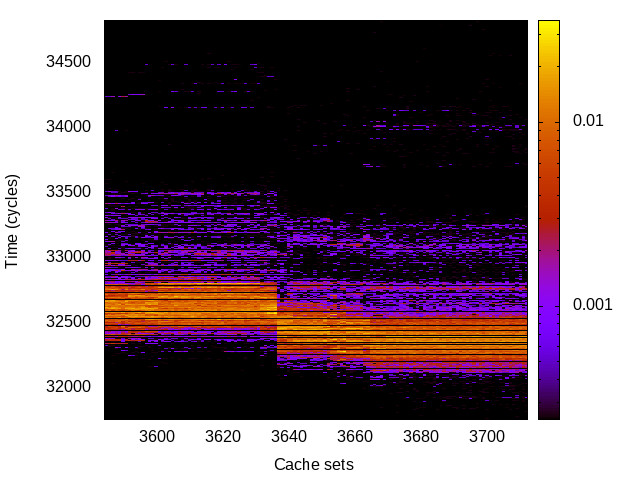
|
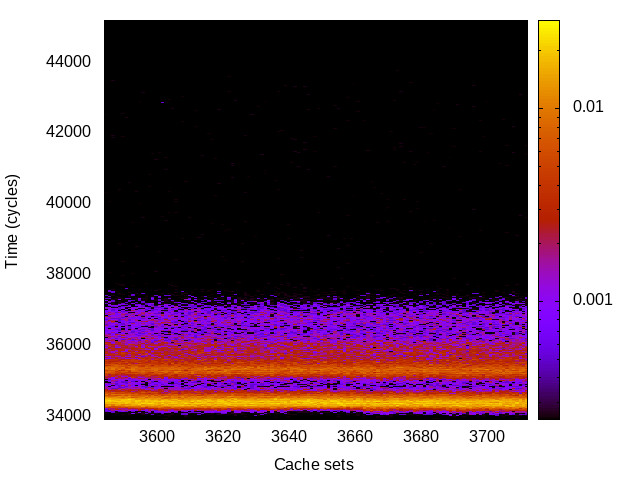
|
| BHB |
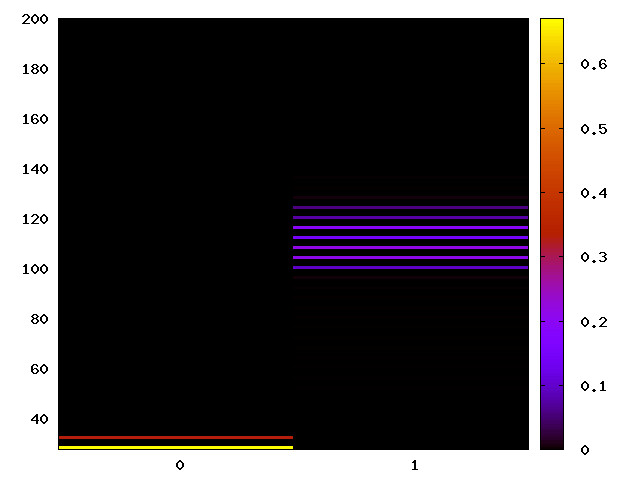
|
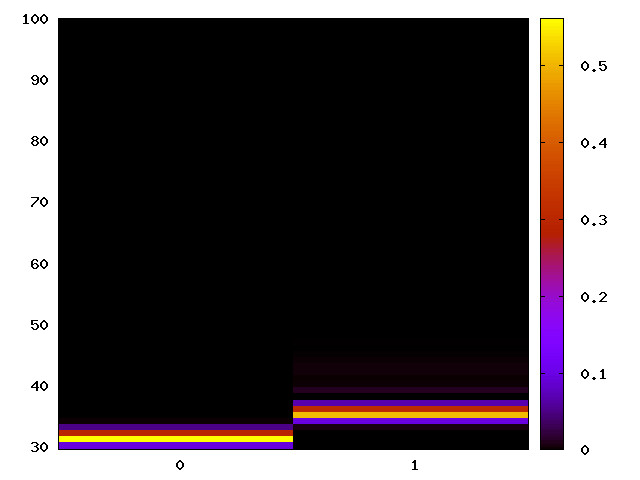
|
Summary of Results
| Channel | Haswell | Skylake | Sabre | Hikey | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| L1-D | 4.0 | 0.0005 | (0.0005) | 4.7 | 0.0008 | (0.0009) | 2.0 | 0.001 | (0.001) | 1.5 | 0.0008 | (0.0008) |
| L1-I | 0.3 | 0.0007 | (0.0008) | 2.1 | 0.0006 | (0.0006) | 2.5 | 0.0013 | (0.0013) | 4.1 | 0.019 | (0.016) |
| 0.02 | (0.0006) | 0.01 | (0.0008) | |||||||||
| TLB | 2.3 | 0.0005 | (0.0005) | 2.1 | 0.0008 | (0.0008) | 0.6 | 0.0005 | (0.0005) | 0.5 | 0.0023 | (0.0024) |
| BTB | 1.5 | 0.0008 | (0.0008) | 0.05 | 0.0014 | (0.0015) | 0.0075 | 0.0041 | (0.0044) | 0.5 | 0.003 | (0.0014) |
| 0.3 | (0.0013) | 0.0021 | (0.0017) | |||||||||
| BHB | 1.0 | 0.0005 | (0.0) | 1.0 | 0.0003 | (0.0003) | 1.0 | 0.0 | (0.0005) | 1.0 | 0.04 | (0.0) |
| 0.6 | (0.0) | 0.02 | (0.02) | |||||||||
We can see from those results that, thanks to the recent addition of the IBC mechanism on Intel platforms, it is possible to close all channels on those processors, while before the availability of IBC there were significant uncloseable channels. But note that our scrubbing depends on flushing the I- and D-caches. On Intel platforms, this is presently only supported on a flush of the full cache hierarchy, which is prohibitively expensive. To make these defences practical, Intel would have to provide a targeted L1-cache flush operation.
On ARM we see that all channels can be closed on the older Sabre platform, which uses an in-order A9 core, while the newer, out-of-order A53-based Hikey has a number of uncloseable channels.